Article originally posted on InfoQ. Visit InfoQ
Transcript
MacCarthaigh: My name is Colm, I’m an engineer at Amazon Web Services and I’m here to talk about PID loops and about how we use them to keep systems stable. I have a subtitle for this talk, which I went back and forth on whether I should give it or not, which is PID loops come from control theory. This is my third or fourth talk, different talk about control theory in the last year. Back in January, I did a workshop where we looked at control theory with a bunch of practitioners and academics who do formal verification of systems.
The conclusion I’ve reached in that year is that control theory is just an unbelievably rich vein of knowledge and expertise and insight into how to control systems, how to keep systems stable, which are very much part of what I do. I work at Amazon Web Services where we have all these cloud services, big distributed systems and keeping them live and running is obviously a very important task, and really digging into control theory, reading books about it, getting into the literature, talking to experts, it’s like finding literally a hundred years of written-down expertise that just all applied to my field that we seem not to know about.
The title for this whole track that we’re doing here is about CS in the modern world. I think it’s a travesty that we don’t teach control theory as part of computer science generally. It’s commonly part of engineering and physics and that’s where I first learned it. I did physics in college, and it amazes me how much relevancy there is in there. Like it says here, the fruit is so low hanging; there are so many things to learn that it’s touching the ground. We could just take these lessons away. In fact, you can spend just a week or two reading about control theory, and you will be in the 99th percentile of all people in computer science who know anything about control theory, and you’ll be an instant expert and it gives you superpowers, some of which I’m going to talk about, to really get insights into how systems can be built better. It’s fascinating and nothing excites me more right now.
I’m going to start with something that’s a little meta. Back in late last year, AWS has a big conference called re:Invent. I gave a talk which was one of the series of talks there, too. We actually gave some let’s-open-the-curtains talks about how we build things internally, how we design systems, how we analyze them. My colleague Peter Vosshall gave one about how we think about blast radius and I gave one about just how we control systems, and just a small bit in the middle I was talking about this stuff, control theory, because I didn’t have time to go into too much detail.
Cindy [Sridharan] reached out after and contacted me and said, “That material looks pretty interesting. Let’s get some more on that,” and here I’m a QCon. I did something, I gave a talk, somebody observed it, gave me feedback, and now I’m reacting and giving that talk. Congratulations, that is 99% of control theory. It applies to almost everything in life, not just how we control stable systems and analyze them and make sure that they’re safe, but business processes too. I’ve seen it crop up in really strange places.
I was talking to a sales team and they were telling me the first thing they do when they go into a new field area and they have to get leads and sell products and so on, they just start measuring. They just start measuring their success rate so that they can identify their wins and build on them and identify their losses and correct whatever they need to correct. It just fascinated me, they’re basically taking a control theory period process to even a very high-level task, like how to sell things. It doesn’t apply to engineering things.
Control Theory
If you’re not familiar with control theory, if you’ve never heard about it, didn’t even know it existed, it’s about a hundred-year-old field. It evolved independently in several different branches of science. There are a few competing arguments as to where the first discoverers, where the chemists claim it was first discovered when analyzing chemical reactions, the physicists claim it was first discovered when studying thermodynamics and engineers have been using it for mechanical control systems and so on. Eventually, all these different fields realized, “Hey, we have these same equations and same approaches that turn out are very general.” They’re about controlling things, getting intent. We want to make the world a certain way and getting the world into that state. It turns out there’s a whole branch of science around it.
I’m going to give you real examples, places where we’re using this just to give you a flavor of what control theory does. My real goal is I’m going to try and give you jumping-off points to places where you can take things and then take them on your own and maybe dig in deeper if this excites you and interests you. There’s lots of Prior Art. At QCon in San Francisco just a few months ago, was a great talk on control theory where Valerie goes into a really good formal approach into how some container scaling systems can be modeled and approached in a control theory framework, and it’s talk well worth watching. There’s more math in that talk than there will be in my talk. If you’re really excited by calculus, look up that talk. It’s a really good one.
There are books on this subject, thankfully, I’ve read both these books. They’re pretty good. The feedback control book is very directly applicable to our field. If you’re controlling computers and distributed systems and so on. The second book, Designing Distributed Control Systems, was not really written with computer systems in mind. When they talk about their distributed systems, they’re actually talking about big real-world machines where not everything’s connected and talking to one another. As you see, there’s a logging machine on the front cover. Obviously, it’s got nothing to do with, say, running S3 or system I work on. It turns out it has a lot of patterns and a lot of lessons in it that directly apply to our field. It’s amazing how much I keep coming back to it.
I see control theory crop up directly in my job, because I go to a lot of design reviews. I’m a principal engineer at AWS and one of my jobs is a team wants to build something or is in the process of building something, they’ll have some design reviews, and they’ll invite some people, and often I’m there, and we’re looking at the system and whether it’s going to work and what we can do with it, and I do the same with customers. There are sets of customers I meet pretty frequently where we were talking about how they’re going to move to the cloud, what are they building in the process, what did their systems look like?
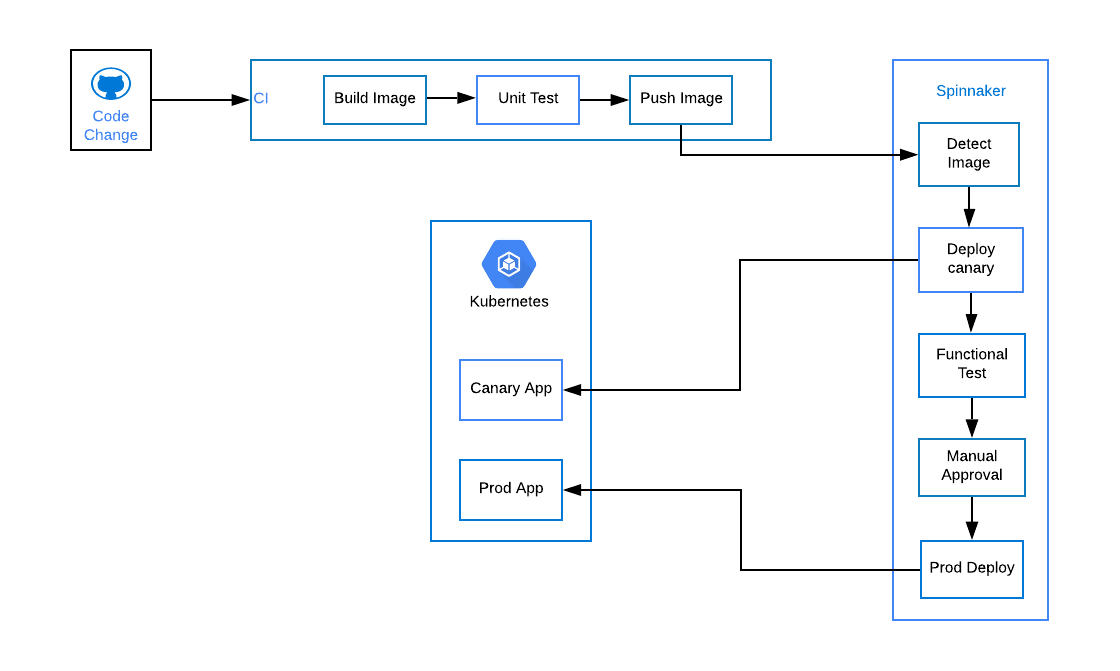
I see a lot of places where control theory is directly applicable but rarely applied. Auto-scaling and placement are really obvious examples, we’re going to walk through some, but another is fairness algorithms. A really common fairness algorithm is how TCP achieves fairness. You’ve got all these network users and you want to give them all a fair slice. Turns out that a PID loop it’s what’s happening. In system stability, how do we absorb errors, recover from those errors? I’ll give you some examples.
The Furnace
No talk focused on control theory would be complete without a really classic example, which is a furnace. If you were learning control theory at the university, this would be the very first example anyone would pick out and I’m not going to do anything any different, but it’s a good example because it’s so easy to follow. Imagine we’ve got a tank of water and we’ve got a heat source, and we want to get the tank to a known temperature. We can vary the heat source. We can turn it up, we can turn it down, we can make it hotter, we can make it cooler. How you would go about doing this is obvious, you would measure the temperature of the water and then if the water is too cold, you turn the heat up, and if the water is too hot, you turn the heat off or you turn the heat down if it’s approaching our temperature, really simple stuff.
It turns out that control theory has a lot to say about how this can be done stably, there are a lot of very naive approaches. If you just have a really big fire and you just keep it under the furnace for a long time, until exactly you measure the right temperature and you just remove the heat, it’ll probably start cooling down really quickly. Or you can overheat in some cases where there’s lag, because the place you’re measuring in the tank of water is maybe not being convected too efficiently, and the rest of the water isn’t at that temperature.
Control theory is the science and analysis of figuring out how to get this right, how to make it stable. It has a lot to say, the biggest thing it has to say, is that you should approach the system in terms of measuring its error. I’ve got a desired temperature, let’s say, I want to get this water to 100 degree Celsius – I’m European, so someone will have to translate – which is boiling temperature, and starts off at room temperature, which is about 20 degrees Celsius. In that case the error is 80 degrees Celsius. We focus on the error, what is the distance from the desired state that we want it get to.
A simple kind of controller is a P controller. That’s a proportionate controller, where all we do is we take some action proportionate to the error. The error is 80, so I keep the heat high, then it goes to 70, 60, 50, and I gradually turn down the heat as it goes. That’s a proportional controller, really simple control system. You would think that would just get to the line and go really just fine. In reality, a proportional controller will tend to oscillate because there are natural lags in the system and there’s no perfect way to measure things, as we all know, so we’ll just hover above the line and it won’t be a perfectly stable system.
To improve on that, we don’t just act in proportion to the error, we use an integral of the error, too. That’s just fancy math for saying we take the whole area under the curve of that error. We take some action that’s proportionate to how much error we’ve had over a period of time, and when you add that you’ve got a PI controller. You’ve got a proportional component, you’ve got an integral component that’ll still tend to oscillate, but far less. It’ll tend to close to asymptote the line you’re trying to hit, trying to get things to a target temperature.
Many real-world systems are PI controllers, potentially the thermostat and HVAC system in this room or cruise control in your car and so on. Control theory in it’s really refined sense actually says, well even a PI controller isn’t perfectly stable, and the reason is if this system were to suffer a big shock, if a lot of water were to suddenly to be taken out of the tank, it won’t react well; there’ll be just too much noise in the measuring signal, and it’ll overdrive or underdrive the system.
To correct for that, you need the derivative component. That’s where PID comes from: a proportional-integral and a derivative component. Control there actually says you can’t be a completely stable system without all three. Even in the real world, there’s a lot of PI controllers, there are theoretical shocks they may not be able to absorb. If you can build a mental model of analyzing systems through this framework – we’re going to go through a few – it can give you really simple insights, and you can very quickly determine that a system may not be stable or safe or needs correction in some way.
Autoscaling
This is the example of a furnace, it’s pretty much the exact same graph and the exact same response for an auto-scaling system. Autoscaling is a fancy furnace, there’s not much else going on. In the case of an autoscaling system, we’re measuring some target metric, say CPU utilization on a fleet. Let’s say I’ve got 10 EC2 Instances and my goal is that none of them should be more than 20% of CPU or something like that, which would be a typical value. It seems low, but people pick those values because they want very responsive latencies, and they don’t want Q’s building up, or garbage collection and all those kinds of things.
We measure its state and we see what’s the CPU. If it’s way below 20, then the system can be, “You’ve got too many hosts, I’m going to scale you down,” just like turning the heat off. Then the CPU starts to rise a bit because the fleet gets a little bit more contented now that there are fewer boxes, and you can see what’s going to happen. Eventually, it’ll get small enough that the CPU will go above 20% on whatever the remaining number of hosts are, and we’ll start scaling out again, or vertically or horizontally, whatever way the system has been tuned to scale. The autoscaling system that we’ve built – we haven’t had a direct EC2 autoscaling system, you can use it to provision instances. This is exactly how it works. We have also have autoscaling systems that are built into our elastic load balancer, that are built into how we provision storage or if you’re using a service like DynamoDB, how many storage slices to use to give you a certain amount of IOPS, and so on. This is the exact kind of control system that’s going on behind the scenes.
They get fancier over time, a simple PI controller will do pretty good job, but it’s maybe not as optimal or as efficient as something with more knowledge can be. As an example, something we launched pretty recently that’s part of our auto-scaling service, is we launched support for machine learning-based forecasting, which is incredible. What we can do is we can actually look at your metric and say, “This is the metric that you want to hit overtime. You want to be this 20%,” and so on. We can analyze our metric using techniques like Fourier analysis that break it down into constituent frequencies. A lot of metrics that we look at, a lot of people’s daily load patterns, are daily load patterns. They also have a weekly load pattern. Every day is maybe busy in the evenings, if it’s, say, an entertainment service, people watching videos or something like that. Then every week, maybe Friday night is your busiest week, because that’s our busiest day of the week. Then you might have busier days or quieter days across a year because of holidays and sporting events.
That kind of analysis can find these patterns and then they can be forecast. We can replay them into the future and see what’s going to happen. We can apply machine learning techniques to it. We have inference models that can figure out what they think is going to happen next and prescale before they’re going to happen. This looks like a machine learning feature, but to me, looking at this system through the lens of a PID controller, this is just a fancy integral. This is the “I” component of a PID controller. What I’m trying to do is I’m trying to look at my total history and project a little into the future. Integration is a form of forecasting and so it still fits in my PID control model, and can still be analyzed in that way, and I’ve tested it out, I’ve done a few things. Along those things, you can play with different values and see how the system responds as you would expect a PID controller to work, and it does.
Placement and Fairness
That’s a really simple straightforward application of a PID controller. A less simple one and less common one is, we can auto-scale when we’ve got elastic capacity. We can take users wherever they are in the world and send them to their closest best region that I’m operating in. We can scale elastically so that everybody can be serviced by their absolutely best region. That’s great when I’ve got elastic capacity, but when I’ve got fixed capacity, we also have a CDN, Amazon CloudFront, and that’s got fixed relatively static capacity. When we build a cloud for insight, it goes in there with a certain number of machines, we put some racks in a room, and it’s got those machines and actually the count might go slightly down over time because there’s a failure rate and not everything gets replaced instantaneously.
They have the capacity they have. Just like launching an EC2 Instance, I can’t just go in tomorrow and add another rack. It takes a bit of planning and there’s a whole procedure for that. You might think this is somewhere where figuring out which side can take which users, how could a PID controller help there? One easy way to do a system here would be, figure out what the capacity of each site is. Figure out your peak time of every single day, and then make sure that at that peak time, no site would be overwhelmed. Only allocate each site enough close users so that you’re not going to overwhelm each site. That’s very inefficient, because at night when things are a bit less busy, there are lots of users who might be slightly better serviced by a site, but they’re going to maybe their second or their third-best site, which it’s just not optimal and actually ends up just because of the way time zones work and people having different periods of activity across the world, leads to suboptimal packing.
Something we do in CloudFront is we run a control system. We’re constantly measuring the utilization of each site and depending on that utilization, we figure out what’s our error, how far are we from optimized? We change the mass or radius of effect of each site, so that at our really busy time of day, really close to peak, it’s servicing everybody in that city, everybody directly around it drawing those in, but that at our quieter time of day can extend a little further and go out. It’s a big system of dynamic springs all interconnected, all with PID loops. It’s amazing how optimal a system like that can be, and how applying a system like that has increased our effectiveness as a CDN provider. We now stream quite a lot of video that people are watching at home. A pretty high percentage of it is hosted on CloudFront these days and I think a lot of that’s due directly in part to that control system.
X-Ray Vision: Open Loops
These are straightforward examples of where we’d applied PID loops, I’m going to go through some more. I wanted to give us more of a mental model and some jumping-off points and ways of utilizing PID theory more directly in our daily lives and our daily jobs. When I gave this talk back in November, I said that if you go to the effort of really understanding control theory, it can be like a superpower. It can really help you deep dive into these systems, and the superpower I think is X-Ray vision, because you can really nail some things. The first of five patterns then I’m just going to go through into what I see as common anti-patterns or common lessons from control theory that I see us miss in real-world designs, the first is Open Loops.
It’s very natural when you’re building a control system, something needs to do something. I’ve got to get a config onto 10 boxes, I’ve got to launch 10 instances. It’s natural to have a script or write a system that just does those things in that order. We’ve probably all seen scripts like this, at small scale they work fine. If you’re doing things manually, this is how we do manual actions as well, but systems like this are an Open Loop. They’re just doing actions, and nothing is really checking if those actions occur. We’ve gotten really good at building reliable infrastructure, and in some ways too good. It works so reliably, you just do it time after time, you never really notice. Well, what if it failed one day? Something’s going to go wrong. That can creep into systems in very dangerous ways.
A surprising number of control systems are just like this, they’re just Open Loops. I can’t count the number of customers I’ve gone through control systems with and they told me, “We have this system that pushes out some states, some configuration and sometimes it doesn’t do it.” They don’t really know why, but they have built this other button that they press that basically starts everything all over, and it gets there the next time, and some cases they even have their support personnel at the end of a phone line. That’s what they do, they get a complaint from one of their customers saying, “I took an action, I set a setting and it didn’t happen.” and they have this magic button, they press it and it syncs all the config out again and it’s fixed.
I find that scary, because what it’s saying is nothing’s actually monitoring the system. Nothing’s really checking that everything is as it should be. Already every day they’re getting this creep from what the state should be, and if they ever had a really big problem, like a big shock in the system, it clearly wouldn’t be able to self-repair, helpfully, which is not what you want. Another common reason for Open Loops is when actions are just infrequent. If it’s an action that you’re not taking really often, odds are it’s just an Open Loop. It’s relying on people to fix things, not the system itself.
There are two complementary tools in the chest that we all have these days, that really help combat Open Loops. The first is Chaos Engineering. If you actually deliberately go break things a lot, that tends to find a lot of Open Loops and make it obvious that they have to be fixed. It drives me crazy a little because I find that you can probably just think through a lot of the things Chaos Engineering will find, and that can be quicker. Then the other is observability, what this problem space demand is, we’ve got to be monitoring things. We’ve really got to be keeping an eye on it.
We have two observability systems at AWS, CloudWatch, and X-Ray. One of the things I didn’t appreciate until I joined AWS – I was a bit going on like Charlie and the chocolate factory, and seeing the insides. I expected to see all sorts of cool algorithms and all sorts of fancy techniques and things that I just never imagined. It was a little bit of that, there was some of that once I got inside working, but mostly what I found was really mundane, people were just doing a lot of things at scale that I didn’t realize. One of those things was just the sheer volume of monitoring. The number of metrics we keep on, every single host, every single system, I still find staggering.
We’ve made collecting those metrics extremely cheap and then we collect them as much as possible and that helps us close all these loops. That helps us build systems where we can detect drift and we can make sure they’re heading for stable states and not heading for unstable states. We try to avoid infrequent actions. If we have a process that’s happening once a year, it’s almost certainly doomed to failure. If it’s happening once a day, it’s probably ok.
My classic favorite example of this as an Open Loop process, is certificate rotation. I happened to work on TLS a lot, it’s something I spent a lot of my time on. Not a week goes by without some major website having a certificate outage. Often it’s because they’ve got a three-year or a one-year certificate and they put it on their boxes. They’re, “I don’t have to think about it for another year or three”, and then the person leaves and there’s nothing really monitoring it, nobody’s getting an email, and then that day comes and the certificate isn’t valid anymore and we’re in trouble.
A really common Open Loop is credential management in general, of which this is just one example. Everywhere else we built, we have this problem too, we have to keep a lot of certificates in sync, so we built our own certificate management system and we actually made it public. We use this ourselves, it’s tied into EOB and CloudFront and a bunch of things. Amazon manager is monitoring certificates as well, looking for any drift, making sure that the load balancer that should have things really has them, that a CloudFront distribution that should have it really has it.
It’s even possible to monitor and alert and so on and uncertified expiry times if you’ve loaded them in manually. The magic to fixing these Open Loops is to really think about measuring first, like I said with that earliest example about just taking feedback and integrating that, but approaching systems design as, “I’m not going to write a script or a control system that just does X, then Y, then Z.” Instead, I’m going to approach it as, “I’m going to describe my desired state, so it’s a bit more declarative, and then I’m going to write a system that drives everything to that desired state.” It was a very different shape of systems. You’ll just write your code very differently when you’ve got that mental model.
In my experience, that model is far better, because it is a closed-loop from day one, far better because they tend to be more succinct ways to just describe these systems, far better because it can also be dual purpose. Often your provisioning system can be the same as a control system. For example, you show up on day one and you’ve got a new region to build in our case, or availability zone to build. You can just run your control plane and it starts off and the error is, I don’t have any of my hosts so provision them, because that’s what it’s meant to do. That’s what it’s built to do, and it ends up having a dual role, which is cool.
If you’re into form of verification like I am, it is vastly easier when you get to the stage where you can formally verify something to verify declarative systems, systems that have their state described like that. It’s just easier, the tools are more structured that way. We’ve been doing a bunch of this, we’ve got papers out where we’ve shown how we use TLA plus, CryptoWall, and you can search for those if you’re interested. We also use tools like F-star and Coke, which are pretty awesome and useful for verifying these kinds of systems. That’s the first X-Ray vision, superpower, look for open loops.
X-Ray Vision: Power Laws
The second is about Power Laws, and it’s about looking for power laws and systems and how to fight them. The reason for this is to do deal with another mental model that I have, which is around how errors propagate. Imagine your distributed system, in my case the cloud, as this one big uniform collection of boxes. These boxes might represent hosts or applications or processes or however granular you want. These could be every tiny little bit of memory on every device in your entire system. Someday an error happens somewhere that you didn’t really plan for – an exception is thrown, a box chokes up, a piece of hardware fails. Well, in distributed systems, that box has dependencies, they tend to fail then, too, especially if they’re synchronous systems.
Now these other things that we’re talking to are failing in unpredictable ways and that spreads. Like any network effect, when things are interconnected, they tend to exhibit power laws and how they spread, because things just exponentially increase at each layer. That’s what we’re fighting in system stability, that’s the problem and it’s a really tough one. Our primary mechanism for fighting this at Amazon Web Services is we compartmentalize. We just don’t let ourselves have really big systems. We instead try to have cellular systems, like our availability zones and regions that are really strongly isolated, errors we can’t even think about, just won’t spread.
That’s been working pretty well for us and also as a lesson from control theory. A lot of the literature in control theory talks about if you’ve got a critical system, dividing it up into compartments and controlling them independently at the cost of maybe some optimality, tends to be worth that. A good example there is a nuclear power plant. Typically, each reactor is controlled independently, because the risk of having one control system for all of them just isn’t worth it. That helps, but that still means you could have an error that propagates to infect the whole compartment, but we want to be able to fight that. We need our own power laws that can fight back, things that can push in the other direction. These are like those integral and derivative components. These are things that can drive the system into the state we want.
Exponential Back-off is a really strong example. Exponential Back-off is basically an integral, an error happens and we retry, a second later if that fails, then we wait. An exponentially increasing amount of time, three seconds, then 10 seconds, then 100 seconds. It’s clearly exponential and it’s clearly acting based on the total history and that really helps. In fact, it’s the only way to drive an overloaded system back to stability, is with some exponential Back-off. Very powerful.
Rate limiters are like derivatives, they’re just rate estimators and what’s going on and deciding what’s to let in and what to let out. We’ve built both of these into the AWS SDKs. If you’re using the S3 client or DynamoDB client, these are built-in and we’ve really finally tuned these things. We’ve tuned them, got the appropriate amounts of jitter, they’ve got the appropriate amounts of back-off. Then we also rate limit the retries themselves so that we don’t get crazy distributed retry storms that can take down entire systems. We’ve really focused to make the back pressure as efficient and effective as we think it needs to be.
This is not an easy problem, there’s a whole science and control theory called loop tuning, about getting all these little parameters perfectly optimal. I think there are about four or five years of history now gone into AWS SDKs, and how we’re trying to get this right and we’re constantly trying to improve it. It’s pretty cool and worth copying.
We’ve got other back pressure strategies too, we’ve got systems where servers can tell clients, “Back off, please, I’m a little busy right now,” all those things working together. If I look at system design and it doesn’t have any of this, if it doesn’t have exponential back-off, if it doesn’t have rate-limiters in some place, if it’s not able to fight some power-law that I think might arise due to errors propagating, that tells me I need to be a bit more worried and start digging deeper. There’s also a great paper – or a blog post, I should say – by Marc Brooker, my colleague, which you can search for, where he goes into some really fine-grain detail about how the stuff we put into the SDKs actually works. That’s the second of five patterns.
X-Ray Vision: Liveliness and Lag
The third is about Liveliness and Lag. Pretty much any control system is doomed to failure if it’s operating on old information. Old information can be even worse than no information. If we were controlling the temperature in this room based on the temperature 30 minutes ago, that’s just not going to work because there weren’t so many people in the room at that time and the information’s just false and it’s going to heat it up too much, it’s no good. This can crop up a lot, and the reason this can crop up a lot in distributed systems is we often use workflows to do things.
Workflows can start just taking variable amounts of time. As the workflow grows and we put more work in it, it can just start taking longer to do things, and also reporting back metrics. Getting information back can also become laggy, especially when you’ve got a really busy day or a really chaotic event, lots of stuff going on, and that can result in ephemeral shocks to the system. Huge spikes in load or a sudden decrease in capacity can become unrecoverable, because the system just becomes overwhelmed and then the lag starts driving the system, and it can never really get back into the state it wants to be.
The underlying reason for a lot of this is because we use FIFOs for most things, I’ll get to that in a second. The bulletproof fix for these systems is impractical and very expensive, but it’s to do everything everywhere in constant time. A simple example of that is, let’s say I’ve got a configuration file and it’s got some user parameters in it that they can set. One way to build that system is, user sets parameter, we’ll just push that little diff or delta out to the system. Works great until lots of users changed their settings at the same time, if you’ve got some correlated condition. Now the system gets super laggy. A different way to build it would be we’ll just push all the state every time, especially if it’s not too big, that can be practical, but it gets expensive for really big systems. The same for measuring things; measure everything all the time. Well, we’re a little bit better about that, but that tends to be how monitoring systems work.
We have some systems at AWS – our most critical systems – where we’ve built this pattern in. Our systems for doing DNS health checks, networking health checks, they’re so critical to availability. They have to work, even during the most critical events, even during when there’s total chaos. They absolutely have to work, so we’ve built those as completely constant time systems. When you set up a roof of the tree health check, that’s pinging your website to see if it’s healthy or not, and should your traffic load go to this webserver in this zone or this web server in this other zone, that’s happening at the same rate all the time and the information about it is being relayed back all the time. It’s healthy or unhealthy, not “It went from healthy to unhealthy,” so only send that delta back. That makes it really robust and reliable.
If you do need a queue or a workflow, think carefully about how deep that should be allowed to grow. In general, we want to keep them really short, if they get too long, it’s best to return errors. That’s a lesson I’ve heard restated from so many different places, that I think it’s an extremely deep one. For information channels if you’re relaying back metrics and so on, LIFO is commonly overlooked, and it’s a great strategy. A LIFO queue does exactly what we want here and will always prioritize liveliness, it will always give you the most recent information, and it’ll backfill when it has some capacity, any previous information, it’s the best of both worlds. It’s rarely seen, you rarely see LIFOs in information systems. Ours are, but I don’t know why it’s not more common.
X-Ray Vision: False Functions
My fourth pattern, and a short and simple one, is to look for False Functions. The thing you’re measuring, you want it to be like a real function. You want it to be something that moves in a predictable way, that is something you’re actually trying to control. It’s common for there to be many dimensions of utilization in a distributed system. As a simple example, let’s say we’ve got a web server and it’s taking requests. As load goes up, CPU goes up at a certain rate because of SSL handshakes and whatnot. Memory consumption goes up at a certain rate because of overloads, and maybe I’ve got a caching system and my cache utilization goes up at a different rate, all different rates. They all have their own functions.
What can happen is that someone, we don’t always perceive that these are different things and we instead measure some synthetic variable that’s a fake function of all three. It’s like looking at the max of all three, and that doesn’t work, it turns out not to be predictable. You haven’t really dimensionalized the system. This all is a complicated process control theory way to say that the Unix load metric is evil and will bite you, because the Unix load metric or a network latency or queue depth metrics in general – Unix load is a queue depth metric – is the compound of so many other things that are going on, that it doesn’t really behave in a linear way. You’ve got to get at the underlying variables.
A lot of systems that are built just on measuring load tend to be chaotic and not really able to correctly control. We’ve found that it’s best to measure some of the underlying things. CPU turns out to be surprisingly reliable, it’s surprising to me because I spend a lot of time working on low-level CPU architecture, and I know how complicated CPU pipelines are, but it turns out at the macro level, just measuring CPU percentage can be very effective.
X-Ray Vision: Edge Triggering
My last pattern is about edge triggering. What edge triggering is, is you’ve got a system, we’re heating our furnace. Let’s say we just keep the heat on, and it gets all the way to the target temperature, and then once it gets to the target temperature, we turn the heat off. That is an edge-triggered system, we triggered at the edge, and only at the edge. There’s a lot of control theory and a lot of debate about edge-triggered systems versus level-triggered system. They can even be modeled in terms of one another.
I like to watch out for edge triggering in systems, it tends to be an anti-pattern. One reason is because edge triggering seems to imply a modal behavior. You cross the line, you kick into a new mode, that mode is probably rarely tested and it’s now being kicked into at a time of high stress, that’s really dangerous. Another is that edge triggering, when you think about it, needs us to solve to deliver exactly once problem, which nobody has solved or ever will solve, because what if you missed that message? What if your system is, “I just send an alarm when I crossed the line”? What if that gets dropped? Now I’ve got to retry it.
Your system has to be idempotent, if you’re going to build an idempotent system, you might as well make a level-triggered system in the first place, because generally, the only benefit of building an edge-triggered system is it doesn’t have to be idempotent. I like to see edge triggering only from humans if I’m alerting a human, actually sending them a page or something like that. For control systems, it’s usually an anti-pattern. It’s better instead to be measuring that level, like we said.
That gets us to the end of all my patterns. The biggest one is to look for the system being measured. Honestly, you’ll be surprised how many times you will just notice that the system isn’t really being measured or observed, and that’s enough to really improve the stability a lot. If you learn and look into all these techniques, they’re highly leveraged, like, I said, the fruits touching the ground, it’s pretty cool.
Questions and Answers
Participant 1: Because we have used machine learning for the first four patterns, why can we not use that in the edge triggering system to load the edge just before the high-stress point and that becomes a pattern again? Why is it an anti-pattern then?
MacCarthaigh: You’re asking, if we just give ourselves some margin of error, if we put the line even a little bit lower, wouldn’t that improve safety? You can absolutely do that, but in high shock or high-stress situations, you’ll never guarantee that there isn’t too much lag between those things, that you just don’t have time to correct. Another is, there’s an entire area of control theory designed around exactly what you’re talking about, which is called hysteresis, which is just almost exactly that property and you can totally do it. It just gets really complicated really quickly, and level triggering tends to be far simpler. Your intuition is right though, it can be done.
Participant 2: You mentioned three variables, P, I and D. Can you give me an example of a system that will not recover from a stress? I missed this part, I don’t understand, what does it mean? The system is, let’s say, auto-scaling scenario. Can you give an example of a stressful scenario where a similar system would not recover?
MacCarthaigh: Yes. If we merely had a P controller, for example, for auto-scaling, and we suddenly lost half the capacity, half the servers died, what would happen is the error would go up so quickly and the remaining hosts, that a P controller would way overscale the system, and then load would go down so much, because there were so many more hosts, so then it would scale it back in again and it would just oscillate like that for quite a while. That’s what we mean by instability in the context of a control system.
Participant 3: Thanks for the talk, really good insights. We quite often have this situation, which was just asked, when we have a relatively stable load and then a sudden spike which we can’t actually predict. My question will be, what would be the direction to look into, maybe in these control systems, how to properly respond? Usually, the problem is that the response time is too slow. We can’t scale that fast, and we need to know before that and it’s not that predictable.
MacCarthaigh: I don’t have an answer, we have not yet built pre-cognition, which I would love. Our main focus for that AWS has been to build systems that are just inherently at more capacity. For example, one of the differences between application load bouncer, our main layer seven load bouncer, and our network load balancer, is their network load bouncers are scaled to five gigabits per second, minimum millions of connections per second, can do terabytes ultimately. We barely even need to control them, just because the headroom is so high. That’s how we’re trying to fix that, and then meanwhile for other systems, while we just have to react and scale as quickly as possible, and we’ve been trying to get our launch times down as low as possible. We can now scale and launch EC2 Instances in seconds which helps, but there’s no other fix for that. There’s nothing we can do in a controller that can magic away the unpredictable.
Participant 4: You talked about back-off retry, all that stuff being really important. What sort of process frameworks, tools, do you have to have to make it really easy for teams to do that?
MacCarthaigh: At AWS we try to bake those into our requests libraries directly. We have an internal library system called CAL, which we build all of our clients and servers on and we just make it the default, it’s in there. Then for our customers and ourselves, because we use the SDKs as well, we’ve got our SDKs and we bake it all in there and the SDK team that maintains all that, they think a lot about this stuff. We just try to make it the default that comes out of the box, and not have to educate customers or expect anybody to do anything different than the default. That’s been very successful.
Participant 5: In control theory, the most gain that we can get is to move the control points to as close to the pole. I think in resource management, it’s not the case. It’d be great to have insight of where we actually take the point in between the stably versus the performance.
MacCarthaigh: I’m not sure I’ve heard all the questions, sorry.
Participant 5: From the given resources that we can get, for example computation resources from there, when we reach pursuing the more and more stable systems then we tend to actually lose the maximum capacity that we can expand.
MacCarthaigh: There is definitely tension between stability and optimality, and in general, the more finely-tuned you want to make a system to achieve absolute optimality, the more risk you are of being able to drive it into an unstable state. There are people who do entire PIDs on nothing else then finding that balance for one system. Oil refineries are a good example, where the oil industry will pay people a lot of money just to optimize that, even very slightly. Computer Science, in my opinion, and distributed systems, are nowhere near that level of advanced control theory practice yet. We have a long way to go. We’re still down at the baby steps of, “We’ll at least measure it.”
See more presentations with transcripts





 Visual Studio Code – my installed extensions
Visual Studio Code – my installed extensions Visual Studio Code intellisense for Machine Learning project
Visual Studio Code intellisense for Machine Learning project