Month: February 2021

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
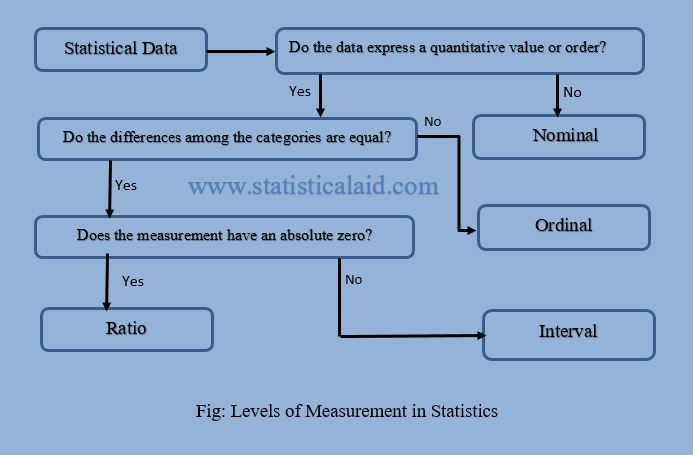
Image Source: Statistical Aid: A School of Statistics
Definition
In statistics, the statistical data whether qualitative or quantitative, are generated or obtain through some measurement or some observational process. Measurement is essentially the task of assigning numbers to observations according to certain rules. The way in which the numbers are assigned to observations determines the scale of measurement being used. There are four level of measurements in statistics. They are-
- Nominal Level
- Ordinal Level
- Interval Level
- Ratio Level
Nominal Level of Measurement
All qualitative measurements are nominal, regardless of whether the categories are designed by names (male, female) or numerals (bank account no., id no etc.). In nominal level of measurement, the categories differ from one another only in names. In other words, one category of a characteristic is not higher or lower, greater or smaller than the other category. For example, gender (male or female), religion (Muslim, Hindu or others), etc. The nominal level of measurement gives rise to nominal data.
We must ensure that the categories of nominal level of measurement must be follow some important properties. They are-
- The categories are must be homogeneous.
- The categories are mutually exclusive and exhaustive.
Ordinal level of Measurement
In ordinal level of measurement there exist an ordered relationship among the categories. For example, we use less, more, higher, greater, lower etc. for define the categories such as costly, less profitable, more difficult etc. More precisely, the relationships are expressed in terms of the algebra of inequalities: a less than b (a<b) or is greater than b (a>b). So, the socio-economic status (low, medium, high), academic performance (poor, good, very good), agreement on some issue (strongly disagree, disagree, agree, strongly agree) are some practical variable of ordinal level of measurement. Ordinal level of measurement gives ordinal data.
Ordinal level maintains some important properties as,
- The categories are distinct, mutually exclusive and exhaustive.
- The categories are possible to be ranked or ordered.
- The distance from one category to the other is not necessarily constant.
Interval Level of Measurement
The interval level of measurement includes all the properties of the nominal and ordinal level of measurement but it has an additional property that the difference (interval) between the values is known and constant size. In this measurement 0 is used as an arbitrary point. The interval measurement scale has some important properties. They are-
- The data classifications are mutually exclusive and exhaustive.
- The data can be meaningfully ranked or ordered.
- The difference between the categories is known and constant.
For example, in Gregorian calendar 0 is used to separate B.C. and A.D. We refer to the years before 0 as B.C. and to those after 0 as A.D. Incidentally 0 is a hypothetical date in the Gregorian calendar because there never was a year 0.
Another example, a thermometer measures temperature in degrees, which are of the same size at any point of the scale. The difference between 200C and 210C is the same as the difference between 120C and 130C. The temperature 120C, 130C, 200C, 210C can be ranked and the differences between the temperatures can easily be determined. When the temperature is 00C, it means not the absence of heat but it is cold. In fact, 00C is equal to 320F.
Ratio level of Measurement
In ratio level, there is an ordered relationship among the categories where exist an absolute zero and follow the all properties of nominal level of measurement. All quantitative data fall under the ratio level of measurement. For example, wages, stock price, sales value, age, height, weight, etc. are the real life variable of ratio level measurement. If we say the sales value is 0, then there is no sale.
There exist some important properties in this level. They are-
- The categories are mutually exclusive and exhaustive.
- The categories can be ordered or ranked.
- The differences among the categories are constant.
- There exist an absolute zero point.
MMS • Thiago Custodio Jeffrey Richter
Article originally posted on InfoQ. Visit InfoQ
Recently Microsoft released a new version of its Azure .NET SDKs, available as a series of NuGet packages designed to provide a consistent and familiar interface to access Azure services from your .NET applications.
InfoQ interviewed Jeffrey Richter, a software architect on the Azure SDK team who worked on the design of the SDKs for various languages and many Azure services.
InfoQ: Why Microsoft decided to launch a brand new .NET SDK for its Azure services?
Jeffrey Richter: There are many reasons for this. For starters, every Azure service team was responsible for its own SDK and this meant that they were all different and customers had to learn each SDK from scratch; there was no consistency. We’d like Azure to look like a holistic platform that customers enjoy using and we want customers to start using new Azure services easily and be productive.
Second, we wanted the new SDKs to embrace cloud/distributed systems features such as cancellation, retries, and logging.
Third, we wanted the SDKs to have a sustainable architecture which allows features and changes to happen quickly without breaking existing customers. The HTTP pipeline we have enables a lot of this and, in fact, customers can extend this pipeline themselves and add their own features! For the older SDKs, we’ve had feature requests that we are just not able to accommodate in a non-breaking fashion due to the technical debt.
Fourth, we wanted to bring these same concepts to all SDK languages. Today, this includes .NET, Java, TypeScript, Python, C, C++, Go, Android, and iOS. And finally, we wanted a design that allows customers to easily diagnose their own problems. With distributed systems, many things can go wrong: network connections, credentials, timeouts, and so on. Our SDK design focuses heavily on mechanisms to help customers such as request ID generation, logging, distributed tracing, and error handling/messages.
InfoQ: In the blog post “Inside the Azure SDK Architecture“, you’ve mentioned the possibility to add custom policies to the HTTP pipeline. Can you give us a few possible scenarios where custom policies could be used?
Richter: Sure. Each SDK client library defines one or more XxxClient classes; each class knows how to talk to an Azure service. When constructing an XxxClient, you pass the service’s endpoint, credentials, and a set of options (like retry or logging options). The options are used to create an HTTP pipeline which is owned by that XxxClient object. All HTTP requests and responses go through this pipeline. The pipeline’s purpose is to apply consistent behavior to all XxxClient methods.
Yes, customers can create their own policy classes and insert instances of them into the pipeline. One example would be to implement client-side caching. The customer can insert a policy that sees that an HTTP request is being made, checks some local storage to see if the requested data is available and then simply returns it without communicating with the Azure service. If the data is not available, then the policy can call the Azure service, get the response, cache it locally (for a future request), and then return.
Another possible policy would be to implement the circuit-breaker pattern. We don’t have this today in our SDKs but we have considered adding this in the future. But a customer could easily implement this today if they choose. Customers could also create their own policies to support mocking and fault injection for reliability testing of their application.
InfoQ: You’ve mentioned the performance of the new SDK. Can you share some benchmarks of the new version compared with the previous versions?
Richter: Well, the performance of any given operation is overwhelmingly attributed to the service processing and network latency. By comparison, the client-side processing is minimal. That being said, the new SDK architecture ensures that XxxClient objects are sharable meaning that memory usage is less than the older SDKs and so there will be fewer garbage collections which improves performance.
Also, XxxClient objects are thread-safe with a lock only being taken when a credential updates its password or token. This allows a single XxxClient object to be used by multiple threads concurrently without any blocking; this also improves performance. The amount of performance improvement is dependent on your application and how it uses these XxxClient objects.
InfoQ: In your blog post, you’ve mentioned formalized patterns in order to increase the developer productivity. Can you explain what they are and give us a few samples?
Richter: Sure, the formalized patterns ensure that all the new Azure SDKs work the same way. Once you learn one of them, adopting another leverages your existing knowledge allowing you to focus on the new Azure service you’re interacting with. Here are a few of our formalized patterns:
- Use an XxxClient class to have your application communicate with an Azure service.
- Create the XxxClient using an endpoint, credentials, and options.
- Each method on the XxxClient invokes one (sometimes more) operation on the Azure service.
- Each method’s operation goes through the HTTP pipeline giving consistent behavior for retry, logging, etc.
- Each method offers cancellation; important to prevent the client app from hanging due to a slow-responding service.
By the way, we publish all our Azure SDK guidelines for all our languages; you can find them here.
InfoQ: What would be the steps in order to move from previous versions to the new SDK? Is it possible to easily migrate or there is no compatibility at all?
Richter: Unfortunately, the new SDKs are not compatible with previous SDKs. There was just no way to accomplish all we wanted to without making significant changes. However, developers can continue to use old SDKs and also use the new SDKs. That is, write new code against the new SDKs and then, over time, modify the old code to use the new SDKs ultimately removing the technical debt of the old SDKs.
Again, a big focus of the new SDKs is to have a sustainable architecture which we can iterate on for decades to come. So, we do not expect to break customers again for the foreseeable future and therefore customers should have great confidence in the new SDKs.
About the Interviewee
Jeffrey Richter is a software architect on the Azure SDK team and helps on the design of the SDKs for various languages and many Azure services, and is a member on the Azure HTTP/REST API Review Board, which review HTTP APIs for Azure service teams looking for correctness, consistency, common patterns, versioning, sustainability, and idempotency. He is also on the Azure Breaking Change Review Board where he meets with Azure service teams that would like to make breaking changes to their service.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

The latest release of GitLab introduces over 60 new features, mostly aimed to improve support for DevSecOps at scale and to better handle the complexity of automation at scale.
On the DevSecOps front, GitLab new Security Alert Dashboard provides a dashboard for security alerts.
Users can now configure Container Network Policies to send alerts to the security alert dashboard. This is especially useful when traffic must be closely monitored but cannot be blocked entirely without negatively impacting the business.
The Security Alert Dashboard lists all alerts that were triggered based on your threat monitoring policies. Alerts can be in one of four possible statuses: unreviewed, in review, resolved, and dismissed.
The Security Dashboard also monitors coverage-guided fuzz tests of your Python and JavaScript apps. Coverage fuzz testing exercises your apps using random inputs with the goal of making it crash and uncover potential vulnerabilities. Fuzz tested apps are instrumented by GitLab to provide rich debugging information. Besides Python and JavaScript, GitLab also supports fuzz testing for other languages, including C/C++, Go, Rust, Java, and many more.
To simplify maintenance tasks and reduce downtime, GitLab 13.9 offers its new Maintenance Mode. When using this mode, all external operations that change the system state are blocked. That includes PostgreSQL, files, repos, and so on. This will have the effect of quickly draining the pipeline of pending operations, while no new operations will be admitted. This will in turn make maintenance tasks run more quickly, says GitLab.
As mentioned, GitLab 13.9 also brings new automation capabilities, which according to the company will make DevOps promise of “delivering better products, faster” truer. In particular, a new !reference tags can be used in the definition of a CI/CD pipeline to reuse a part of a task configuration.
Additionally, for complex CI/CD pipelines made of multiple files connected using include and extends, it can become hard to keep a full comprehension of what is going on. To mitigate this, GitLab 13.9 makes it possible to merge all pieces of a pipeline together to better understand the overall flow and simplify debugging. Similarly, pipelines that span across multiple projects and pipelines that have child pipelines can now use resource groups to ensure only one deployment pipeline runs at a time, thus removing the risks of concurrent execution. For example, when running a child pipeline, GitLab waits until any already executing pipeline finishes before running the child.
On a related note, GitLab has quickly issue a mainenance 13.9.1 release that fixes a number of bugs and regressions.
GitLab 13.9 includes far more new features than what can be covered here, so make sure you read the official announcement if interested.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Vitalik Buterin (https://vitalik.ca) conceptualized Ethereum (https://ethereum.org) in November, 2013. The core idea proposed was the development of a Turing-complete language that allows the development of arbitrary programs (smart contracts) for blockchain and Decentralized Applications (DApps). This concept is in contrast to Bitcoin, where the scripting language is limited and only allows necessary operations.
The EVM is a simple stack-based execution machine that runs bytecode instructions to transform the system state from one state to another. The EVM is a Turing-complete machine but is limited by the amount of gas that is required to run any instruction. This means that infinite loops that can result in denial-of-service attacks are not possible due to gas requirements. The EVM also supports exception handling should exceptions occur, such as not having enough gas or providing invalid instructions, in which case the machine would immediately halt and return the error to the executing agent.
The EVM is an entirely isolated and sandboxed runtime environment. The code that runs on the EVM does not have access to any external resources such as a network or filesystem. This results in increased security, deterministic execution, and allows untrusted code (code that can be run by anyone) to be executed on Ethereum blockchain.
As mentioned earlier, the EVM is a stack-based architecture. The EVM is big-endian by design, and it uses 256-bit-wide words. This word size allows for Keccak 256-bit hash and ECC computations.
There are three main types of storage available for contracts and the EVM:
- Memory: The first type is called memory or volatile memory, which is a word-addressed byte array. When a contract finishes its code execution, the memory is cleared. It is akin to the concept of RAM. write operations to the memory can be of 8 or 256 bits, whereas read operations are limited to 256-bit words. Memory is unlimited but constrained by gas fee requirements.
- Storage: The other type is called storage, which is a key-value store and is permanently persisted on the blockchain. Keys and values are each 256 bits wide. It is allocated to all accounts on the blockchain. As a security measure, storage is only accessible by its own respective CAs. It can be thought of as hard disk storage.
- Stack: EVM is a stack-based machine, and thus performs all computations in a data area called the stack. All in-memory values are also stored in the stack. It has a maximum depth of 1024 elements and supports the word size of 256 bits.
The storage associated with the EVM is a word-addressable word array that is non-volatile and is maintained as part of the system state. Keys and values are 32 bytes in size and storage. The program code is stored in virtual read-only memory (virtual ROM) that is accessible using the CODECOPY instruction. The CODECOPY instruction copies the program code into the main memory. Initially, all storage and memory are set to zero in the EVM.
The following diagram shows the design of the EVM where the virtual ROM stores the program code that is copied into the main memory using the CODECOPY instruction. The main memory is then read by the EVM by referring to the program counter and executes instructions step by step. The program counter and EVM stack are updated accordingly with each instruction execution:
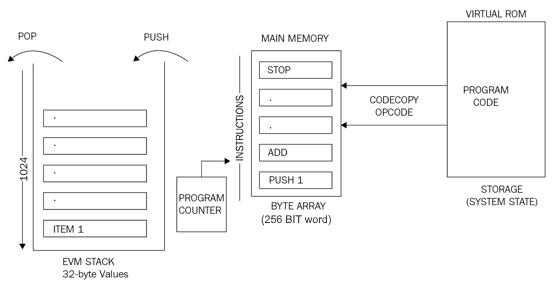
Figure 1: EVM operation
The preceding diagram shows an EVM stack on the left side showing that elements are pushed and popped from the stack. It also shows that a program counter is maintained, and is incremented with instructions being read from the main memory. The main memory gets the program code from the virtual ROM/storage via the CODECOPY instruction.
EVM optimization is an active area of research, and recent research has suggested that the EVM can be optimized and tuned to a very fine degree to achieve high performance. Research and development on Ethereum WebAssembly (ewasm)—an Ethereum-flavored iteration of WebAssembly—is already underway. WebAssembly (Wasm) was developed by Google, Mozilla, and Microsoft, and is now being designed as an open standard by the W3C community group. Wasm aims to be able to run machine code in the browser that will result in execution at native speed. More information and GitHub repository of Ethereum-flavored Wasm is available at https://github.com/ewasm.
Another intermediate language called YUL, which can compile to various backends such as the EVM and ewasm, is under development. More information on this language can be found at https://solidity.readthedocs.io/en/latest/yul.html.
Execution environment
There are some key elements that are required by the execution environment to execute the code. The key parameters are provided by the execution agent; for example, a transaction. These are listed as follows:
- The system state.
- The remaining gas for execution.
- The address of the account that owns the executing code.
- The address of the sender of the transaction. This is the originating address of this execution (it can be different from the sender).
- The gas price of the transaction that initiated the execution.
- Input data or transaction data depending on the type of executing agent. This is a byte array; in the case of a message call, if the execution agent is a transaction, then the transaction data is included as input data.
- The address of the account that initiated the code execution or transaction sender. This is the address of the sender in case the code execution is initiated by a transaction; otherwise, it is the address of the account.
- The value or transaction value. This is the amount in Wei. If the execution agent is a transaction, then it is the transaction value.
- The code to be executed presented as a byte array that the iterator function picks up in each execution cycle.
- The block header of the current block.
- The number of message calls or contract creation transactions (CALLs or CREATE2s) currently in execution.
- Permission to make modifications to the state.
The execution environment can be visualized as a tuple of ten elements, as follows:
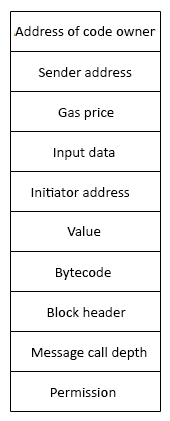
Figure 2: Execution environment tuple
The execution results in producing the resulting state, the gas remaining after the execution, the self-destruct or suicide set, log series, and any gas refunds.
The machine state
The machine state is also maintained internally, and updated after each execution cycle of the EVM. An iterator function (detailed in the next section) runs in the EVM, which outputs the results of a single cycle of the state machine.
The machine state is a tuple that consists of the following elements:
- Available gas
- The program counter, which is a positive integer of up to 256.
- The contents of the memory (a series of zeroes of size 2256)
- The active number of words in memory (counting continuously from position 0)
- The contents of the stack
The EVM is designed to handle exceptions and will halt (stop execution) if any of the following exceptions should occur:
- Not having enough gas required for execution
- Invalid instructions
- Insufficient stack items
- Invalid destination of jump opcodes
- Invalid stack size (greater than 1,024)
Machine state can be viewed as a tuple, as shown in the following diagram:

Figure 3: Machine state tuple
The iterator function
The iterator function mentioned earlier performs various vital functions that are used to set the next state of the machine and eventually the world state. These functions include the following:
- It fetches the next instruction from a byte array where the machine code is stored in the execution environment.
- It adds/removes (PUSH/POP) items from the stack accordingly.
- Gas is reduced according to the gas cost of the instructions/opcodes. It increments the Program Counter (PC).
The EVM is also able to halt in normal conditions if STOP, SUICIDE, or RETURN opcodes are encountered during the execution cycle.
In this article we saw a detailed introduction to the core components of the EVM. Learn more in Mastering Blockchain, Third Edition by Imran Bashir.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Evolutionary change is about starting where you are and improving one small change at a time. You need a stressor, a reflection mechanism, and an act of leadership to provoke change and institutionalize it. Understanding empathy allows change agents to find out what resonates with someone and work around resistance.
The first version of the Kanban Maturity Model was released in 2018; InfoQ did a Q&A on the book Kanban Maturity Model. Version 1.2 of the Kanban Maturity Model has been released in October 2020; the updates provide information about values that help succeed agile initiatives and transformations, ideas to prevent culture from going back in organizations, and insights on the human condition and understanding empathy.
David Anderson describes the evolutionary theory as “one mutation at a time.” Evolution happens because a solution is chosen, or selected, from a set of alternatives.
According to Anderson, if something is fit for its purpose and fit for the environment, then it will be selected again and again; it will survive and thrive. Evolutionary theory tells us that progress is made in punctuated-equilibrium:
We observe that organizations become settled with a certain behavior that reflects a level of organizational maturity. To improve, we need to disrupt that equilibrium, to make it uncomfortable for them, and then advise or coach them on how to consolidate improvements to establish a new settled equilibrium at a deeper level of maturity.
To provoke changes in selection criteria, you need to introduce stress into the environment, Anderson argues. You need to be able to reflect on the stress and its impact and how it changes fitness and selection, and then you need to take action to change behavior; to change what is being selected.
Understanding what motivates an individual’s behavior and actions is essential for progressing organizational change, according to Teodora Bozheva:
Actions are the answer of an individual who intends to meet their objectives in certain circumstances. Therefore, understanding the context in which people work, what they do and not do, what kind of difficulties they meet to accomplish their objectives, and how they feel doing their job, helps defining appropriate actions for the organization fostering individuals’ engagement in them.
InfoQ interviewed David Anderson and Teodora Bozheva about evolutionary change.
InfoQ: How can understanding empathy help to foster change, and what can we do to increase our understanding?
David Anderson: The dictionary meaning of empathy, “The ability to understand and share the feelings of another”, is inadequate. It can be mistaken for sympathy and pity. Sympathy and pity are low maturity behaviors. True empathy is the ability to walk in someone else´s shoes, to see as they see, feel as they feel, to understand the world as the other person understands it. We do not pity that person, we view them as dignified, as having self-esteem, and a self-image, a place in the world, a contribution to make.
True empathy gives an understanding of behavior and allows a change agent to understand what will resonate with someone, what will be readily accepted, and what will not, and furthermore, why things will be resisted. When we have true empathy, we can anticipate resistance to change and work around it.
InfoQ: Does the new Kanban Maturity model provide insights into the human condition? Can you elaborate on this, on what you have learned?
Teodora Bozheva: The new model shares insights that organizations that already use Kanban Maturity Model (KMM) have come to. Most of them had run Agile initiatives before becoming familiar with KMM and they were strongly focused on creating teams, making people feel confident, happy, and proud of working with their teammates. Understanding the path that KMM draws in front of them helped them realize that developing further the capabilities of the entire organization was also improving the human condition. More precisely, individuals were seeing themselves as more accomplished professionals, capable of leading multiple teams and divisions, dealing with different internal and external factors that affect their services, and successfully managing more complex situations. They aspire to develop their skills and maturity together with developing the human condition of their colleagues. The actions these people take develop real improvement in their organizations.
Anderson: The KMM and the Evolutionary Change Model are designed to be compatible with the human condition. Understanding the neuroscience of the brain and how humans perceive the world around them and their place in it is not new. Some of these ideas are 2500 years old, from Greek philosophy. What is relatively recent is the neuroscience that shows that Plato and Aristotle had remarkably accurate insights into the human condition.
Merging the work of Plato and his student Aristotle, we can say that the human soul has spirit, desire (or appetite), reason, and a need for purpose. The first three map directly to the architecture of the brain and there is a control hierarchy or priority. To motivate change we need to address the needs of each aspect of the human soul. We’ve built all of those concepts into our coaching model for KMM.
InfoQ: How can Kanban be an evolutionary path to agility?
Anderson: The three elements of evolutionary change in organizations are:
1. A stressor
2. A reflection mechanism
3. An act of leadership
The Kanban Method provides the stressors and the reflection mechanisms and has enough variety of practice implementation to do this at each of the maturity levels. To provoke acts of leadership, people need to be held accountable. Accountability means responsibility for an outcome. KMM focuses on outcomes; this is core to the model. In addition, we use the cultural values of the KMM to create an organizational culture that encourages and enables leadership at all levels.
InfoQ: What can be done in agile initiatives to make change sustainable and prevent culture changes from going back in organizations?
Bozheva: The culture of an organization can be seen as a combination of people’s values, behaviors, and interactions. The outcome of an organizational initiative is the effect of the combination of the culture and the actions taken by the company.
Anderson: The word you are looking for is “institutionalization”. What does it take to institutionalize change so that it sticks so that it outlives the current management and the current staff? It lies in individuals, and groups, in their sense of self, and sense of identity. Changes need to become part of who we are, why we exist, what we do, and how we do them. Changes need to be pulled by the people and embraced by the organization as a social group, whether that is a team, a department, a product unit, a business unit, or the entire business.
Institutionalization happens naturally as a side-effect of evolutionary change. The problem with traditional change initiatives is that they are designed and managed; they are not evolutionary. Change is something inflicted upon the people, not pulled by them. The Kanban Method together with the Kanban Maturity Model codifies the means to create institutionalized change.
Increasing Adoption of Informatics will Promote Growth of Data Analytics Outsourcing Market
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Data analytics tools empower associations to settle on better choices, increment effectiveness, decrease operational expenses, give modified contributions, and improve client administrations. Various organizations favor utilizing information investigation to examine huge measure of information through different quantitative and subjective strategies to acquire market and client experiences. There has been a critical expansion in the information created by associations, inferable from more prominent reception of cell phones and online media, and expanding sight and sound substance.
Information Analytics Outsourcing indicates rethinking of information and measurable examination, notwithstanding the utilization of computational assets for powerful dynamic and progressed business answers for outsider merchants. Information or data analytics is the way toward gathering, reviewing and assessing information to make significant data and inference for viable dynamic in the business. Information examination is considered as a significant key that drives better business choices. Information examiner is the individual or calling who is working in the information investigation, performs vital occupation in the information the board and information expert rethinking is to get this assistance from pariah provider. It manages the assortment of information, use of the processing assets and operational and insights exploration to address any sort of issues identified with the business and give progressed business answers for outsider sellers.
Growing Adoption by Retail Industry will Aid in Expansion of Market
Data analytic outsourcing is chaotic and has a tedious cycle for association as it requires some investment and complete consideration and information about the field, in this way, association likes to utilize information expert to examine huge measure of information. There are different methods for examining it, such as subjective and quantitative, essential and optional some of the time absence of gifted individuals in the association likewise drives to rethinks the information. Focal points of the information investigation re-appropriating are to acquire important market bits of knowledge, client experiences and make suitable business methodologies.
Different businesses can profit by information investigation, particularly monetary administrations, medical care, media, correspondences, and retail. The retail business would now be able to discover openings for new items and benefit dependent on market drifts that can be explored carefully through noticing shopper conduct over web-based media and their commitment and purchasing encounters, without experiencing the conventional ways, for example, meetings and studies. Rather than having an in-house programming, organizations are searching for re-appropriating their exploration to an outsider to save money on expenses. The BFSI area drives the information examination rethinking industry with the vast majority of the organizations focusing on this vertical. Nonetheless, arising verticals, for example, assembling, medical care, and IT and telecom likewise are demonstrating high development in this market.
North America to Hold Dominance Owing to Increasing Adoption of Marketing Analysis
Another factor boosting the development of the information examination re-appropriating market is the ubiquity of Internet of things (IoT) as it furnishes advertisers and organizations with occasions to use and make noteworthy bits of knowledge in regards to customers. The new advancements crucial for fruitful execution of IoT drive new business openings. Information examination is quickly creating as Internet of things (IoT) is helping in better dynamic. Examination of data about associated things is one of the critical highlights of Internet of things. Use of IoT builds the measure of information in classification and amount, along these lines introducing the chance for improvement and use of information examination rethinking.
Regionwise, the global data analytics outsourcing market is widespread into the regions of North America, Europe, Asia Pacific, Latin America, and the Middle East and Africa. These regions are further classified into nations. Out of these, North America is at the top position with the largest share on account of the increasing adoption of marketing analytics by industries. This, coupled with the growing demand for advanced data analytics services in companies for offering better quality services to the customers. On the other side, the market in Asia Pacific is likely to witness significant growth in the coming years on account of the rapid industrialization and urbanization with major adoption of data analytics in various end user industries such as banking, retail, e-commerce, and others.
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ

Evan You, the creator of the Vue.js front-end framework, recently released a new major iteration of Vite, a build tool that focuses on build speed and short feedback loops. Vite 2.0 is a complete refactoring of the previous version around a framework-agnostic core. Vite 2.0 features a new plugin format and improved programmatic API that strive to make it easy to build new tools on top of Vite.
You described Vite’s new release as follows:
Vite (French word for “fast”, pronounced
/vit/) is a new kind of build tool for front-end web development. Think a pre-configured dev server + bundler combo, but leaner and faster.
[…] Vite 2.0 brings about many big improvements over its previous incarnation.
Vite 2.0 is now framework-agnostic. Frameworks are supported via plugins, a number of which are already available (e.g., for Vue, React, Preact, LitElement). A Svelte plugin is in the works.
Vite requires a version of Node.js that is equal or posterior to 12.0.0. Project scaffolds to quickly get started can be produced via the command line. The following command creates a Vite project that uses the Preact front-end framework:
npm init @vitejs/app my-preact-app --template preact
Vite 2.0 has a new plugin format that extends Rollup’s plugin interface. The Rollup extension results in Vite’s new plugin system being compatible with many existing Rollup plugins. A list of compatible Rollup plugins is maintained online. The list includes commonly used plugins such as eslint (static code analysis), image (image file imports), replace (replaces strings in files while bundling), GraphQL (converts GraphQL files to ES6 modules), and more.
A Rollup plugin is an object with a set of properties, build hooks, and output generation hooks that configure the behavior of the bundler at specific points of its processing. A Vite-compatible Rollup plugin that transforms (preprocesses) custom file types is as simple as:
const fileRegex = /.(my-file-ext)$/
export default function myPlugin() {
return {
name: 'transform-file',
transform(src, id) {
if (fileRegex.test(id)) {
return {
code: compileFileToJS(src),
map: null
}
}
}
}
}
Surma and Jake Archibald previously lauded the simplicity of the Rollup plugin interface in a talk (Making things fast in the world of build tools) at JSConf Budapest. Archibald credited 16 custom Rollup plugins for allowing them to implement numerous performance optimizations:
You might feel like, we’re, you know, kicking Webpack a lot here. You are right, we are. The honest truth is that the difference that we felt between working on a project with Webpack and working on a project with Rollup was really, really, night and day for us. Not only did we feel like we understood what was happening, we felt capable of changing what was happening if we needed to.
Vite plugins may use only Rollup-compatible hooks. They may also take advantage of Vite-specific hooks and properties (configResolved, configureServer, transformIndexHtml, handleHotUpdate) to customize Vite-only behavior — custom handling of hot module reloading, differential building, and more.
Vite 2.0 is partly inspired by a new range of tools that strive to provide a more productive development experience in modern browsers. The recently released Snowpack 3 touts build time below 50ms independently of codebase size; and streaming imports. Snowpack is used in Svelte’s upcoming application framework SvelteKit and the Microsite static site generator. Preact’s WMR pioneered leveraging the Rollup plugin interface to reuse a large set of battle-tested Rollup plugins. Developers may refer to You’s comparison of Vite vs. Snowpack and WMR.
Vite 2.0 also provides first-class CSS support (with URL rebasing and CSS code splitting), server-side rendering support (experimental), and opt-in legacy browser support.
Vite’s documentation is available online and covers dependency pre-bundling, static asset handling, production bundles, server-side rendering, back-end integration, and more. Vite is distributed under the MIT open-source license. Contributions are welcome and must follow Vite’s contributing guide.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

In a recent NY Times feature article, Noam Scheiber provided a pretty thorough picture of the mid-to-longer term economic challenges we’re facing and some of the alternative policies that the Biden administration may pursue to address them. The most important forces driving things boil down to a few:
- Manufacturing that has a high labor component is almost universally cheaper to do outside of the US, where the workforce is paid less (and where worker protections may not be as comprehensive.)
- Automation is increasingly being applied to wring manufacturing jobs out of the economy. For companies, this brings improvements in unit costs, throughput, output and quality.
- Globalization (mostly outsourcing the fabrication of components or finished items) reduces costs to US companies and to US consumers.
- While the US is still leading in invention and Intellectual Property generation, other countries, such as China, realize a lot of the value when they manufacture or assemble goods based on our IP. When the US relies on other countries to manufacture and assemble high-tech products, it loses valuable exposure and on-the-ground experience which should inform ongoing innovation. Scheiber cites research presented in a “2012 book by the Harvard business professors Gary Pisano and Willy Shih [that] made the case that when it comes to manufacturing, strength yields strength, and weakness yields weakness. They showed that the offshoring to Asia of the consumer-electronics industry, which executives believed was becoming too commoditized to be worth keeping entirely in the U.S., had weakened America’s so-called industrial commons — the ecosystem of research, engineering and manufacturing know-how that creates innovative products. In effect, getting out of the business of making stereos and TVs in the 1960s and ’70s made it harder for American manufacturers to produce more sophisticated technologies like advanced batteries. The Chinese, of course, took the other side of the bet — gaining know-how by starting with simpler products, which then led to the making of more sophisticated ones. That’s partly why the China shock started with exports of products like textiles and steel and eventually included smartphones.”
- As some industries wink out of existence in the US, there isn’t anywhere for a lot of their displaced employees to go, especially in exurban or rural areas.
Education could certainly be an important part of the answer to some of these issues, but there are numerous impediments. Out-of-work miners or factory workers are not good prospects to become robotics programmers and maintenance technicians. (See this NY Times article about Mined Minds, a failed program intended to turn out-of-work miners in West Virginia into web developers. Mined Minds is currently the defendant in a suit brought by a number of its students.)
A November 2020 whitepaper by the Baker Institute presents a model based on data from 1984 to 2016 that shows that automation may not reduce the number of jobs, overall, but it will increase inequality by diminishing prospects for workers that cannot attain knowledge worker status. The whitepaper’s authors present the job of a librarian as an example. Some of a librarian’s work, such as tracking lent-out materials and replacing returned items to the shelves, is essentially manual and automatable. Some, such as advising users about available resources, is not. At least, not yet. In any event, automating what can be automated would reduce the need for some number of librarians, even though all of them are presumably accomplished knowledge workers. It’s possible some of the displaced librarians could be educated to manage the automation that displaced them, but there is no reason to believe that they would be more qualified than anyone else to do so just because the technology would be applied in the setting in which they used to work.
In his article, Scheiber asserts that “The Biden team initially focused on job creation that didn’t require massive retraining or relocation.” and “In Zoom call after Zoom call, he pleaded with [his policy staff] to identify jobs in manufacturing and energy that would not require workers to undergo years of retraining or uproot their families.”
Herein, I believe, lies the crux of an intractable problem—using industrial policy to paper over a structural problem might provide some immediate relief but it does nothing to address underlying issues. Kicking the can down the road like this might be palliative for the moment while we are in a dire situation, but it will not position us better for the future. Unfortunately, we can’t just educate ourselves out of this mess with the EIC we have in order to suppress the pain and dislocation in a systematic way. In addition, nationalist, protectionist policies could ultimately end up being counterproductive and “. . . might encounter resistance from some of Biden’s own advisers and much of the party’s policymaking elite, who tend to consider such economic nationalism counterproductive and passé. . . Treasury secretary, Janet Yellen, said just last year that the manufacturing diaspora has been a major boon for the global economy.”
Scheiber also observes that “. . . [green new deal] proposals . . . are also somewhat controversial, even on the left, unlike the relief portion of his agenda. In part, that’s because these provisions would most likely increase the price of clean technologies, which can be imported more cheaply from abroad.”
However, “A growing body of evidence on the harm done to workers by a trade agreement with China, which other economists played down at the time, has increasingly vindicated [Dani Rodrik, an economist at Harvard].”
Many policy makers are looking at the potential of education to play a major role in restructuring our economy and, thereby, our society. For example, “Representative Ro Khanna of California, for one, has introduced a bill that would spend $100 billion over five years to fund research in industries like quantum computing, robotics and biotechnology and to situate tech hubs in areas hit hard by deindustrialization. Most of ‘the top 20 universities in the world are American — places like the University of Wisconsin, University of Michigan, which are dispersed across the country,’ says Khanna, who represents parts of Silicon Valley and was a co-chair of Bernie Sanders’s presidential campaign. ‘There’s no reason we can’t see innovation and next-generation technology in these communities.’”
This might certainly contribute to US competitiveness, but does it really have the potential to address the needs of displaced factory workers? If they aren’t viable web developers, why should we think that they have the potential to contribute to or even participate meaningfully in leading-edge AI or Quantum Computing projects? It’s attractive to focus investment in education on the leading edge of the wave of innovation but the focus required to help workers displaced by it is at the trailing edge. Instead of allowing the wave to wash over many of these people, we need to get them moving fast enough to at least make it through the backwash and get to shore.
I am a believer in education as an important lever with which to address some of the economic and societal issues we face. It’s clear, though, that goals and outcomes need to be retargeted, it needs to be restructured to deliver on its promise and it must evolve in parallel with the changes we make to address the needs of our citizens. The one-size-fits-all model we essentially have now isn’t what we need.
MMS • Mads Torgersen
Article originally posted on InfoQ. Visit InfoQ

Transcript
Torgersen: I’m Mads Torgersen. I am the current lead designer of C#. I’ve been that for a good half decade now, and worked on the language for about 15 years. It’s just a bit older than that, about two decades old. During that, it’s gone through a phenomenal journey of transformation. Started out as a very classic, very turn of the century mainstream object-oriented language, and has evolved a lot. Many of the things that happened over time, were inspired/borrowed/stolen from the functional world. There’s been a lot of crossover there.
Functional Additions to C# over Time
There are many things that we can talk about here. Just to put a little bit of structure, I’ll start in the past. I’ll talk about the functional stuff we were getting into C# around the time when I first joined 15 years ago, and throughout that period. Where it was very much about staying within the object-oriented paradigm, but trying to enhance it in various ways, in particular, around control flow, and those kinds of things. Then we went into a phase that we’re still in, where the focus was really triggered by the cloud and devices. The fact that much more than in the distant past that many of you probably don’t remember, data is something that is shared between many different applications, concurrently. That’s a scenario where in some sense, history is on the side of functional programming. This is a point in time where we had to not just enhance object-oriented programming, but provide an alternative within the C# language, to supplement the object-oriented programming with making a more functional paradigm easier within the language. Then finally, we can talk a little bit about the future. Some of the thoughts we have in different directions being inspired by functional programming, including through the type system, how to really get rid of some of the strong dependencies that are a bit of a tax on software development processes in object-oriented programming today. That’s the overall structure of it.
I’m going to spend most of this talk, the two first bullets of these three, I’m going to spend in Visual Studio, which some of you may have heard of. It’s the world’s first and foremost IDE. I’m sure many of you will agree with, and it’s coming from Microsoft. It has excellent support for C#. I am going to go right in there. We’re going to simply take a little journey through the first three versions of C# and all the functional stuff that happened there.
C# 1.0
This is a C# 1.0 program, pretty much, attempting to abstract over some functionality using first class functions. Actually, the very first version of C#, unlike many object-oriented programming languages actually supported first class functions from the get-go. You have function types, you have to declare them. They’re nominal, just like declaring a class or an interface, or a struct, you have to declare a delegate, as we call them. They’re function types. They’re really crappy in many ways. They get the job done. You declare the predicate type here, as something that takes an int and returns a bool. Then I can write a method that takes a predicate, using that type. When I call a method, I have to parse it. There are no function literals yet, so I have to parse it a named method. I can parse it the method GreaterThanFive here, which fits the type structurally, and therefore can be converted to a delegate object, which is a first class function parsed to the filter and applied there. You can see the application of it here. A little calling of p here in call at as a first class function.
That’s all writing in C# from the get-go, which is a little bit of a leg up on some of the other languages. Obviously, it’s fairly clunky, and so on. From a type perspective, it’s not super elegant. That’s something that it shares with most object-oriented languages at the time that the programming world has these two different kinds of polymorphism. Two different ways that you can write code that applies to multiple different types at a time. The functional camp has gone with parametric polymorphism, where you have parameterized over types. Your code is parameterized over types and can be applied to different types. Object-oriented programming had gone with subtype polymorphism, where you have hierarchies of different classes, and they can all pose as the base type and be mixed together, like in collections and so on like that. Both have strengths and weaknesses. Around the turn of the century here, we were all engaged in trying to figure out how to get parametric polymorphism into object-oriented programming languages. To help with things like, I have a collection here that is untyped. I put ints into it but I can’t say that, so I have to cast them as they come out again, and so on. The whole thing is specific to ints, there’s no abstraction over types.
C# 2.0
First thing we do with C# 2.0 is we need parametric polymorphism, we add generics. Now I can make my types generic, so I can make my predicate type generic here and have it apply to all kinds of values, not just ints. That’s very nice. Of course, I need to then say that what I take here in my filter method is that it’s a predicate of int. I can also make methods generic. Many of you who don’t know C#, you also know this from Java, you should not be surprised. The support for generics in C# is different mainly in that it has worked all the way into the runtime. It’s not erased by the compiler. It runs deeper. It’s more complete. I can make my filter method generic as well saying, I can take any predicate, and any array, and return that same array. If I can just replace all the ints with T’s here, I should be able to apply the filter to anything. I should not replace that one. We filter to anything, as long as the T’s match up in the signature. Here you can see that my call to filter doesn’t actually need to parse int explicitly as a type argument. That can be inferred implicitly. There’s a little bit of the type inference that’s also creeping into C# as well. That’s generics.
With generics, arrives the opportunity to have better libraries. That’s a big thing when you add generic, you can add generic libraries. Let’s forget about these old, clunky collections. Let’s have some generic ones. Now we can check this ArrayList on the garbage heap. We can use list of T instead. New generic list. Of course, that is all very nice. Now I don’t have to cast things when I take them out, because they’re already known to be all these benefits. What’s more, list of T can actually have better methods on it, because it knows it’s tight. We could actually just return the calling to ToArray on this accumulator method that we have. We don’t even have to do our own manual building up of the result here. There’s a method for that. Generics really help with the abstraction here. All by taking this functional programming language polymorphism into C# as well.
This should be repetition for people who went through this in real-time. The rest of you who just grew up much later than us, you’ll be like, “That’s completely basic.” This is how it came in to C# and to many object-oriented programming languages of that age. It became the new standard for what should obviously be in any modern language. We can actually do a little better here. Array used to be the only generic type, now we can have other collection types. For instance, we can have one that’s called IEnumerable of T, which abstracts over essentially anything that can be iterated over. We can take IEnumerable of T, and we can return IEnumerable of T. I’m getting sick of writing types all the time, I’ll cheat and use a C# 3.0 feature here and just use type inference on local variables here. IEnumerables can be foreached over just like arrays and everything else.
When I do that, I can now write my method as a generator, which is another thing that came out of the functional world where I am lazily producing the results of this filter, as you ask for them. Instead of having this accumulation into a temporary collection, and returning that, I can simply say, yield return, because this is an old language, we have to have some syntax there. Yield return the value, and then I don’t need the temporary collection. I don’t need to return. I’m simply now writing a generator that whenever the foreach here asks for the next value, the IEnumerable will go say, let me run the next bit of code that produces that. Again, another functional thing that makes it into C# 2.0.
The last thing though, is the first attempt at having function literals or anonymous functions. Instead of having to have a named method for everything that we want to parse as a function, we can get rid of that declared method there. The syntax isn’t beautiful, but this is the first run at a syntax for anonymous functions.
C# 3.0
Now comes C# 3.0, and we want to start addressing scenarios like interoperating with databases. We have what we call language integrated query is the big new thing here. In order to do that, we need to do better on the functional front. First of all, let’s take this clunky syntax and let’s give that a do-over. Let’s have lambda expressions in C# instead. You can write it like this, which isn’t much better. Lambda expressions can optionally have expression bodies, so that gets a little better. Also, we get more type inference. You don’t actually have to say the parameter types of a lambda expression, as long as they are parsed to something that will tell them the type. More type inference here, because we’re calling filter with an array of int, then T will be inferred to be int. Then this is inferred to be a predicate of int, and therefore, int is pushed back down into the lambda and its body is type checked in the context of that. More type inference there.
We also realize that we’re going to be using first class functions a lot, so this whole declaring your own delegates, that really sucks. Functional languages, they have, typically, structural function types. We should get at least closer to that. We can just add a library of generic delegates to C# itself. We now have Func, and that’s a delegate type that’s pre-declared. We have them up to certain number of parameters, which grows for every release, because we want to try to capture bigger functions. We can get rid of that as well. Now we’re down to something that is fairly neat. You saw the var here. We can put var in many places. More type inference. Who needs to see the types all the time? Then, one thing that when you start using something like filter here, you might want to apply more than one filter. Now it gets really annoying because I have to want to apply a filter to this, then I get this nesting going on. Let’s say I want to get all the things that can be divided by three. That just looks really ugly. That becomes a lump of code.
What a functional language would do here is it would have a pipeline operator. It would say, the first parameter there, we can pipe that into a function call with some syntax. C# can’t do this, so I’m just going to wing it here. I could even take the original array, and I could pipe that into the first filter call there, something like this. This is what a functional language would do. We don’t put that into Sharp. What we do instead is we say, ok, you can declare a static method like this, you can declare it as an extension method. That means that it can be called on its first parameter as if it was an instance method on it. Now I can say array.Filter. I can say, that .Filter, and you get that fluent flow that you would get in a functional language as well. Yet another inspiration there. Extension methods really prove their worth in C#.
Of course, querying is a general thing. We add a library called Linq for Language Integrated Query, where you don’t even have to write your own filter method, you can just use the where method from there, and it looks exactly the same way as the filter I just used. We can get rid of that as well. We’re doing some querying here. This is really beautiful, and you can add other query methods. Instead of here, you could have a select method where we transform the result. Let’s say we also add support for little, anonymous record like thing. I could output an anonymous object of x and x-squared or whatever, y equals x-squared, some silly thing. You can put together what looks more like a SQL query. You really like some nice syntax just like SQL. We could say, from x in array, where x less than five, select. You can now write this as a syntactic sugar for the same thing, for stringing together these calls and lambdas. This is a functional construct. This is a list comprehension or query comprehension. It’s monadic. C# has monads in this particular case, and it does the job. That’s the classic phase.
We also add the ability to actually quote lambda expressions so that when you parse them, instead of parsing them to a delegate type, you parse them to another type called expression of T. Instead of getting a lambda function you can execute, you actually get a syntax tree of the lambda at runtime. Code quotations Lisp style comes in at this point. That’s how we build our ORM support, the Object Relational Mapping. When you write a query like this, it gets translated into a tree that can then be parsed to a SQL translator. Turn it into SQL. Parse it to a SQL database, and run the query like that. That was our first functional boost.
Aspect of C# Syntax that Could Be Retired
Randy: Is there any aspect of the C# syntax you would retire?
Torgersen: Yes. Certainly, that first shot at function literals, the anonymous methods was a clunky mistake, and we overrode it immediately in C# 3.0. Of course, we can’t take it out, but coming up with a more flexible lambda syntax. That’s an obvious one. I also think these delegates, I’m not showing the underbelly of the delegate type, the function types, but the way we designed them, they really weren’t designed in C# 1.0 for functional programming. They were designed for programming with events, like supporting subject observer style eventing. They can contain more than one function. They can contain a list of functions. If you execute them, all of those functions will get called and only the last one, you’ll get its result. It’s really hideous. That, I would have a do-over on that whole thing if I could.
How Current and Envisioned Future State of C# Support for Functional Programming Stack Up Against Scala
Randy: How does the current and envisioned future state of C# support for functional programming stack up against for example, Scala, which we know is a purely functional or more functional language?
Torgersen: I love Scala. Some details I don’t like, but I love Scala in its philosophy, which is to produce a genuinely, not so much a multi-paradigm language but a unified paradigm language where everything is carefully worked together. As we add functional things to C#, we try to do it in the same way where they fit well with what’s already there, rather than being a separate part of the language. I really adore that as a philosophy. I don’t think we will get to where C# is a complete balance between functional and object-oriented, we’re always object first. We’re never going to compete with a functional first language like F#, for instance. There are so many things from functional programming, so many idioms, such an amount of type inference that we could never get there from here. It’s in between there. We take these functional things in not because we want to be multi-paradigm, but because there are scenarios where it’s really useful.
Cloud Driven Object-Oriented Programming Encapsulating Functionality and Data
The next wave really is this cloud driven wave where object-oriented programming focuses a lot on encapsulating functionality and data together. That’s great for some scenarios. It really had a golden era and it’s still good for many things. When your data is in the cloud, and is being shared across many different application areas, being used in different ways, then packaging the functionality and the data just doesn’t make sense anymore. There, you really want to have the functions on the outside, not on the inside, which means the core data needs to be public in the data type. It often needs to be immutable, depending on how you architect. You need to be able to do the things that you do by having virtual methods in an object-oriented program, like you have shaped dependent behavior by overriding virtual methods in hierarchy. Those things that shape dependency, you need to be able to express from the outside. You need to write a function that takes some object in, the object doesn’t know about the function, but the function itself does different things depending on the type of the object. That’s what pattern matching is for.
C# 7.0
In C#, fast forward to C# 7.0, we get pattern matching into C#. We start laser focusing on that scenario only, so if you have some static void M that takes an object O. You’ve always been able to say in C#, if (O is string), for instance, and get a Boolean result back. Now when you want to do something about, you’ve lost it as a string. You check that it was a string, and then you lost it. You will say something like Console.WriteLine of String. What if you could just give that string a name while you’re at it? Now you can say string, we can output the string as well, like this, in an interpolated string.
This now is an example of a pattern. Initially, we just allow patterns inside of already existing control structures in C#, so that each expression gets enhanced to not just check against types, but to check against various patterns. Switch statement as well. I can say switch of O, and instead of just comparing against constants in the cases, I’m going to switch syntax. It’s just hideous in C# as well as all the other C-based languages. I can say case, and instead of just using constants here, I can say case string s. Then go do my thing. It’s classic switch stuff where you have to put a break in order to close things out.
We saw the retcon constants as well, like constant values, they were also a pattern. I can also say is null, or things like that. Now patterns have a place in the language. There are only these two patterns pretty much to begin with. Since then we’ve been expanding on what patterns do we have in C# and where can they be used, so that we get more towards the expressiveness of C#. I want to show you an example of that. Since what I showed you, we’ve evolved C# to now have expression bodies in ordinary methods as well. This is an expression body method that takes in some object. Again, it’s trying to apply functionality from the outside of the object model by saying, which thing is this? If it’s a car, then we do one thing. If it’s a taxi, then the pattern is more fancy. It will apply a property pattern to the taxi, and look at its Fares property, and now it applies a constant pattern to it. Say, there’s zero people here, so they have to pay this much to go with the bridge, which is this all four. We have deconstruction in the language now. Bus has a deconstructor, so we can apply a positional pattern. Applying patterns recursively, again, to the parts of the bus.
In this nested switch here, we have relational patterns now coming into C# 9.0. We have logical patterns to and/or not to combine other patterns, and so on. Patterns have gone off as a thing of its own. Of course, this whole thing is not a switch statement but it’s a switch expression, which is much more nifty and modern, and so on. This thing has ballooned over time to be a really expressive part of C# from being not there at all, a couple of versions ago. C# 6, there was no such thing as pattern matching. That’s a big concession to, you need this style of programming to make up for the fact that you can’t wrap the functionality up with your object hierarchy. I think you’re seeing many languages doing the same thing, all driven by the need to work on outside data.
Speaking of outside data, one of the things you often want to do is treat that outside data more as a value, and often also work with it as an immutable value. Here’s an example where this is me before I was married, and then I changed my last name, that’s how you would mutate the thing. We added support for classes like this in C# now to have properties that can only be mutated during initialization. In this object initializer here, when the object is being created, I can still mutate the properties, but I can’t change the last name. If I want to change the last name, I need to create a new record. I need to have an immutable discipline where I create a copy. I copy and modify. I do non-destructive mutation.
Records in C#
In order to support value semantics like that, you now also have records in C#, which come with a bunch of abbreviations and stuff. The main thing they give you, is they give you value semantics by default. Instead of always assuming object-oriented stuff, and you have to overwrite the defaults and write very long things to be immutable and value based, they give you this by default. Instead of creating person.LastName, I can now say var newPerson equals person with LastName equals Torgersen. There’s non-destructive mutation supported in the language on records. More types will come over time to support non-destructive mutation, where you can say it’s like that one with everything copied over. That merged with the object-oriented paradigm. You can see that I’m actually creating an employee here, but I’m only storing it as a person. The new person here will also be an employee and they will also copy over even the things that can’t be seen statically at this point in time. That’s like trying to fit this in with subtype polymorphism. You really need to make sure that non-destructive mutation works well even when you don’t have the whole truth about the actual runtime type of things around at the point where you do the copying and mutation.
The other thing with records is that they have value equality. You compare two records that correspond to comparing all the members and making sure that they’re equal. We take care of generating all that code and the hash code, and also making sure that it’s symmetric. It’s not difficult per se, but it’s a maintenance nightmare to maintain a manually written equals function that is symmetric, and remembers to deal with all the data, and so on. We do that for you as well on records. That’s another step towards functional programming.
Performance Concerns with Immutability
Randy: There were several people wondering about performance concerns with immutability.
Torgersen: This goes pretty much regardless of the programming language features, whether they are nifty or not. Typically, with immutability, that means allocating a lot of objects. In C#, sometimes you can get around that by using structs instead, then you have higher copying costs as well, because structs are value types, and they assign by copy. If they’re big, the lesser evil is to have them be reference types, to be classes. Records here as well are classes. They are objects. We built very big things that use an immutable discipline. The C# compiler is not just a compiler, it’s an API that can give you every syntactic and semantic detail about a C# program. It can help you build more C# code. It’s what’s being used by the C# IDE here, as I’m using the IDE. It’s using incremental APIs and everything. It’s a big API, and the whole data model is immutable. Performance really was a problem. Allocation was a problem as we built. We’ve had to do tricks along the way to share as much as possible, to use structs where we can to cheat, and not copy things where we can, and so on. That’s this scourge of immutable programming. I don’t know that there’s much we can do about it, other than try to tune our garbage collectors for it.
When to Choose a Class versus Record
Randy: When would you choose a class versus a record and vice versa?
Torgersen: Records really are classes with extra bells and whistles. When the defaults of classes reference equality, mutability, when those things are not what you need, that’s when you choose a record, when you need to be value based and potentially immutable. Typically, you don’t have to be immutable. I can totally have a record that’s mutable. C# doesn’t prevent it in any way. You just have to be careful when you have mutable reference types with value equality, because the hash code will change over time. You stick that sucker in a hash table and you mutate it, it can never be found. They’ll be dragons.
The core choice really is, I am working with data from the outside. I’m treating it as data. I’m treating as values. I don’t care about the object. I will have object identity as a reference type, but I don’t care about it. It’s not the important part of the data model. You still have inheritance. You see records inheriting from each other here. Get all that modeling. We might add some shorthands to C# later to give you something like discriminated unions from functional programming. This gets you a fair bit of the way in that you can have these value oriented types where you can create a hierarchy to model the fact that there’s a type with multiple different shapes. This gets you very far out of the way towards discriminated union style semantics.
Static Members in Interfaces
With that, I think I will go to the last bit which is the future. One thing that a few functional languages, notably Haskell, has really nailed, is that in Haskell, they have this thing called type classes that allow you to abstract over some types having a certain number of functions. Then to say that a given type satisfies that type class. When you witness that, you can do that independently of the declaration of either the type class or the concrete type. You have a third place in the code where you put them together. That gives an amazing amount of decoupling. Tight coupling is a bit of a scourge of a lot of programming, including definitely, object-oriented programming. In order for a class to implement abstractions, it has to implement an interface, for instance. It has to say right there that it implements the interface. It has to have pre-knowledge that it was going to be used in the context where the interface makes sense. It’s been interesting for us to study, is there something we can learn from type classes, and flip them into a fully object-oriented feature set that could help us with that?
One thing is that this whole idea of functions on the outside, they’re represented in C# by static members in many object-oriented languages. If an interface could abstract over static members, like static properties, and also operators, which are overloaded in C#, then we could say that int implements this particular thing that has a plus and a zero. If we constrain our generic by it, then we can now write generic numeric algorithms, for instance. That’s nice, talking about the functions that apply to the type rather than just the instance members. We still have the strong coupling here between the int type and it has to know about the IMonoid and implement it.
Extensions
That’s the problem here. What if you could instead say that somewhere else? What if after the fact I could say, here is an extension, if this is in scope for you, then it tells you that int32 implements the IMonoid interface as a third-party declaration. In the scope of this declaration, I know that int32 actually implements this interface, even though the type and the interface didn’t know about each other, inherently. I can even say how it implements the interface in the cases where it doesn’t already. It already has a plus operator, so that’s implied. I can explicitly specify here how the witness here can say exactly how I implement this. That’s a direction that we are thinking about taking the type system. It’s going to be hard to do in practice, but we’re working on it because it can really affect software development and decoupling of components in a way that object-oriented programming needs.
See more presentations with transcripts
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Today, excellent customer service will make your company stand out from your competitors.
But it can get overwhelming for your customer care team, and be costly to employ a 24hr team.
However, with an artificial intelligence (AI) chatbot, you can do more than offer excellent customer service.
But therein lies an enormous problem…
Which platform do you use to build your chatbot? What important characteristics should you look for?
In this post, we will look at the various features you should look for and some of the best platforms.
Let’s get started.
Choosing the Right Platform: What to Look For
AI chatbots can learn new things through pattern tracking and apply them to similar questions and problems. They can help you solve problems, complete tasks, and manage information with no human intervention.
When properly set up, these interactive chatbots can help you increase revenue and optimize costs. They can also:
- Offer support services on social media, websites, and apps.
- Escalate complex problems to human representatives.
- Identify potential customers and get them to join your sales funnel.
- Inform target audiences about your offers and send marketing messages.
But what should you look for when building one?
Deep Understanding
Your AI chatbot should do more than interpret user requests.
It should also have the capability to amalgamate information based on previous conversations. This way, it can deliver comprehensive answers and hold intelligent conversations.
What’s more?
Your AI chatbot should understand a customer’s mood.
Misinterpreting human sentiment and emotions is one common challenge of using AI chatbots. If your chatbot does not respond in the right tone, it could have a negative impact on your business.
Which brings us to the next feature:
Training
Your chatbot should continuously learn and get smarter with each customer interaction through machine learning and semantic modeling.
There should be no need for your team to conduct manual training unless they want to introduce new vocabulary.
Benefits of Using AI Chatbot for Your Website
Conversational chatbots can make your websites interactive and engaging. By engaging visitors in one-on-one conversations, they reduce your bounce rates and improve customer satisfaction.
Need an example?
Let’s say, you own a web hosting company. Besides providing exemplary web hosting services, you should also be available 24×7 to serve your valuable customers and resolve their issues efficiently.
Since live customer care agents can’t be available round-the-clock (plus, they are costly), you can use on-site chatbots to handle the task. Bots are super-efficient, objective, and not prone to mood swings or tiredness. That’s why more and more brands are incorporating chatbots in their customer-facing channels.
Conclusion
Now that you understand what to look for, what options do you have in terms of platforms you can use?
Drop a message in the comments section. I’d love to hear about them.